Today, many courts require filed documents to contain searchable text so clerks and other court staff can find key passages quickly. Submitting a document that is not text-searchable can often lead to rejections.
In addition to converting your document to the required format, our software can automatically generate searchable text in many instances if it detects that your uploaded document doesn't have it.
How it works
After you upload a document in any InfoTrack court filing workflow, InfoTrack analyzes the document to see if it contains any searchable text.
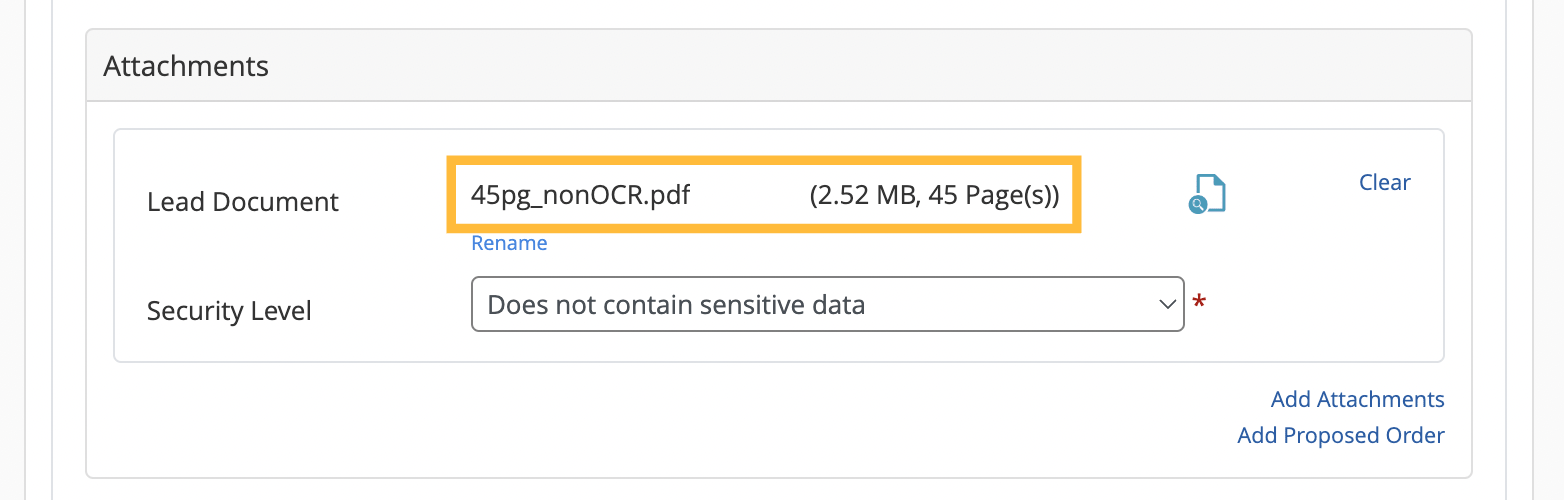
If your document was created in a text editor like Microsoft Word before it was converted to PDF, it likely has text embedded already. If your document is already text searchable, the page count and file size will appear once the green progress bar is complete.
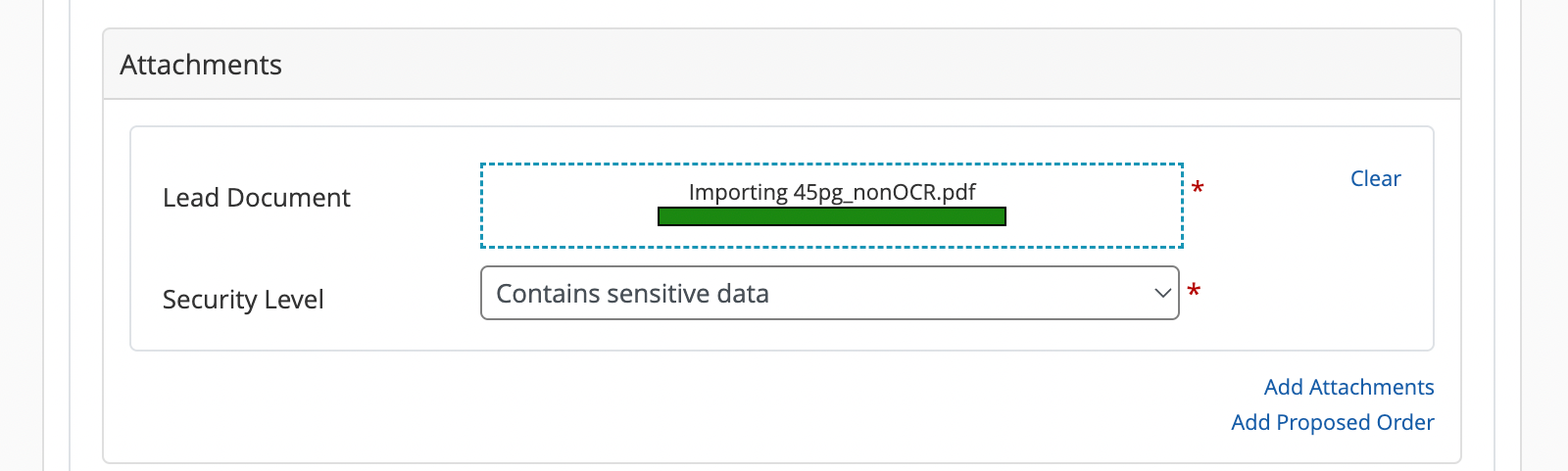
However, if your document started out as an image file (i.e. a scanned picture of a document) rather than a text file, you'll see a spinning pinwheel that indicates that InfoTrack is currently scanning the image to generate searchable text.
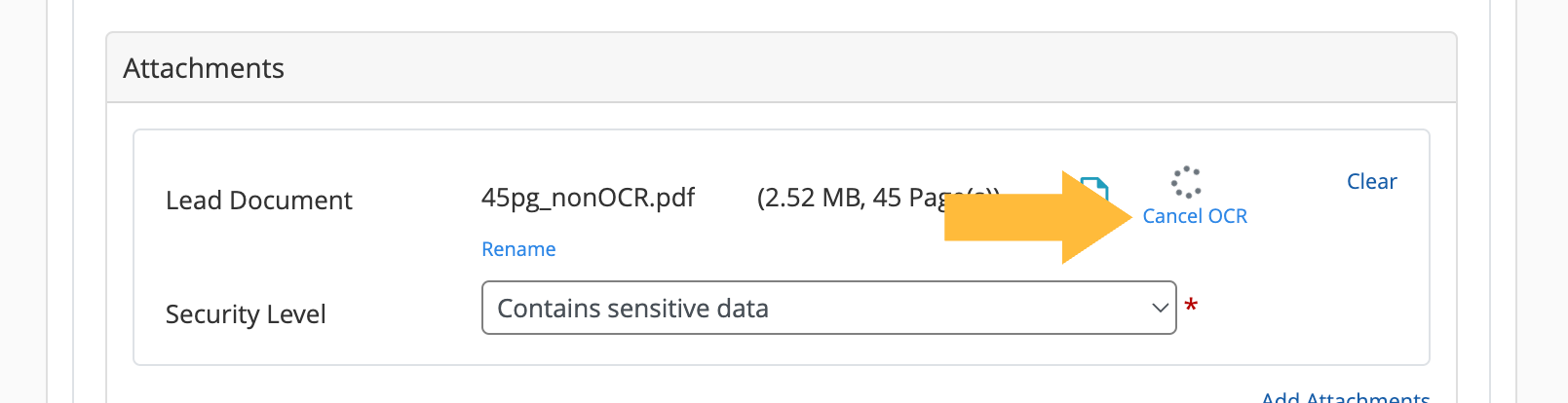
This process may take more than a minute on larger documents. Unless you are sure your court does not require documents to be text searchable, we highly recommend letting it run in the background as you complete the final steps in your court filing.
If you decide that you do not need OCR applied, you can click Cancel OCR and continue with your filing.
Verifying that OCR has worked
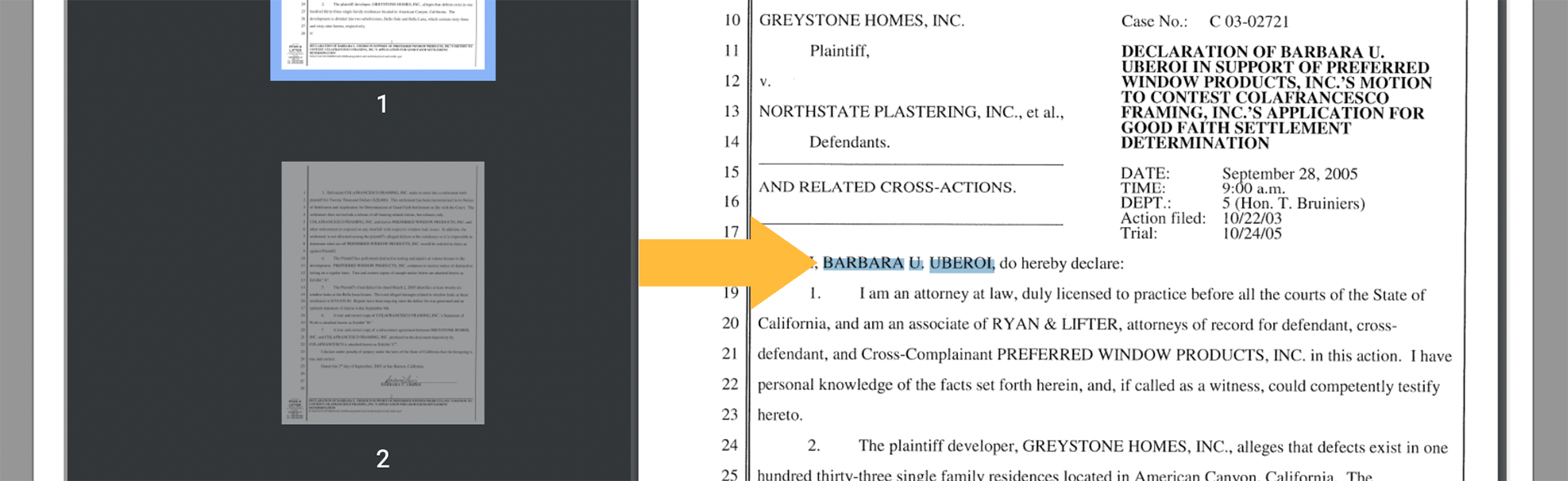
When the pinwheel disappears, you may click the document preview icon to verify that OCR has been successfully applied to your document. If the OCR process worked correctly, clicking and dragging on any text in the document preview should cause the letters to be highlighted in blue, as seen below.
Limitations of OCR
For optical character recognition to work correctly, the text in your document image must be clearly defined. If a human reviewer would have trouble transcribing the document image into text, the software will likely struggle as well.
Common reasons that OCR fails to execute properly on a document image include:
Low resolution
The image is not sharp enough to clearly render each character on the page.
Distortion/obstruction of the text area
If the text is difficult to read in some areas because of a marking on the document, OCR may have a difficult time extracting those passages from the image. This may happen more frequently on photocopied documents, which tend to have extremely bright or dark spots due to their extremely high contrast.
Non-traditional fonts
OCR technology is trained to translate a broad range of serif and sans-serif fonts that are commonly used on legal documents. However, it may struggle with script-style fonts and character sets that use highly stylized curves and angles.